
Bei den Cloud Creators entwickeln wir nicht nur Cloud-Anwendungen für unsere Kunden, sondern übernehmen auf Wunsch auch den Betrieb und die kontinuierliche Wartung von Software und Infrastruktur. Damit dies zuverlässig gelingt müssen wir alle Systeme zentral im Blick haben. Um Metriken kontinuierlich zu erfassen, verwenden wir die Open Source Monitoring Lösung “Prometheus”, Visualisierungen machen wir mit Grafana.

Metriken sammeln mit Prometheus
Prometheus sammelt in regelmäßigen Zeitabständen Messwerte, sog. Metriken, ein und speichert sie zentral ab. So entsteht für jede Metrik eine sog. Zeitreihe, in der der zeitliche Verlauf der Messgröße abgespeichert wird. Bei diesem “Pull”-Ansatz werden die überwachten Systeme aktiv abgefragt. Prometheus eignet sich also gut zur permanenten Überwachung relevanter Größen wie z. B. CPU-Auslastung oder verfügbarer Speicherplatz. Weniger geeignet ist es dagegen zum Erfassen spontan auftretender, unerwarteter Ereignisse.
Da Metriken mehrfach auftreten können, z. B. weil ein Server mehrere CPUs hat oder mehrere Server gleichzeitig überwacht werden, können Metriken in Prometheus mit sog. Labels näher beschrieben werden. Technisch bedeutet das, dass für jede Metrik und für jede Kombination von einzelnen Label-Werten eine neue Zeitreihe entsteht. Während lange Zeitreihen von Prometheus sehr effizient abgespeichert und ausgewertet werden können, kann es zum Problem werden, extrem viele Zeitreihen abzuspeichern, die aber kaum Einträge enthalten. Man spricht in so einem Fall von “High-Cardinality”, der auftreten kann, wenn übermäßig detaillierte Labels verwendet werden. Labels sollten also wohlüberlegt verwendet werden und als Daumenregel angeben, woher eine Messgröße stammt. Insbesondere sollten Labels nicht missbraucht werden, um Informationen zu erfassen, die einen einzelnen Zeitpunkt oder Messwert näher beschreiben. Dafür eignen sich im Zweifel andere Systeme, wie z. B. Loki, besser.
Bereitgestellt werden Prometheus Metriken in Textform über einfache HTTP-Anfragen, entweder direkt durch die zu überwachende Software (z. B. Caddy) oder über eine Vielzahl von sog. Exportern, die Daten aus unterschiedlichen Quellen aufbereiten und im korrekten Format zur Verfügung stellen. Zu den wichtigsten gehört der Node-Exporter, der Metriken von Linux-Servern zusammenträgt. Ein Ausschnitt dieser Metriken im Prometheus Format ist hier zu sehen:
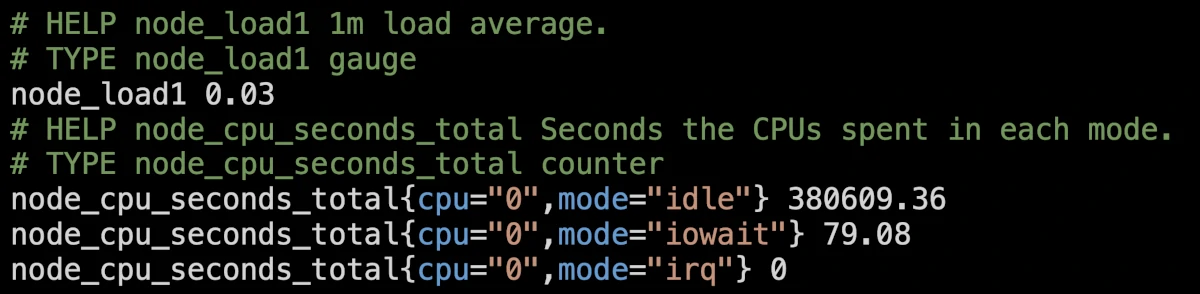
Dabei beschreiben Zeilen, die mit ‘#’ beginnen, die Metrik und ihr Format. Jede Metrik trägt einen Namen und ggf. Labels (in geschweiften Klammern). Der zugehörige Zahlenwert wird dann samt Zeitstempel zur entsprechenden Zeitreihe hinzugefügt.
Metriken von entfernten Servern
Das Internet ist voll von einfachen Beispielen, wie Prometheus Metriken vom lokalen Host sammeln kann. Dasselbe Verfahren funktioniert prinzipiell auch für Metriken, die sich außerhalb des lokalen Netzwerks befinden. Allerdings sind hier besondere Anforderungen an die Sicherheit nötig, schließlich soll nicht jeder auf unsere Messdaten zugreifen können. Hier kommt uns ein besonderes Feature von SSL (bzw. TLS) zugute: bei HTTPS Verbindungen, wie sie im Browser inzwischen zum Glück Standard sind, weist üblicherweise nur der Server seine Identität durch ein vertrauenswürdiges Zertifikat nach, der Server lässt aber beliebige Clients zu. Bei entsprechender Konfiguration ist es allerdings möglich, dass sich auch der Client durch ein gültiges Zertifikat ausweisen muss. Insbesondere für die Kommunikation von Maschinen untereinander, ohne menschliche Interaktion bietet sich dieses sog. TLS Client Auth Verfahren an. In unserem Fall bekommen wir auf diese Weise ein hohes Maß an Sicherheit “gratis” durch die Bordmittel von TLS.
Aktiv sammeln oder Sammler aussenden und warten
Da Prometheus Metriken aktiv abfragen muss, ist es nötig, Prometheus so zu konfigurieren, dass es über sämtliche Systeme und Subsysteme, die es zu überwachen gilt, Bescheid weiß. Das kann manuell passieren oder über verschiedene sog. Service Discovery Methoden. Dennoch kann es recht schnell sehr aufwendig werden, die Konfiguration zu verwalten.
In unserem Fall überwachen wir unterschiedliche Micro-Service Infrastrukturen für verschiedene Kunden. Es wäre also geschickt, den Prometheus-Sammler samt der benötigten Exporter einmal zu Konfigurieren und als Paket auszuspielen und die Daten trotzdem zentral abzuspeichern. Genau das mach der Prometheus-Agent möglich. Integriert in einen gemeinsamen Docker Compose Stack zusammen mit dem Node-Exporter und cAdvisor, sammelt er regelmäßig die lokal verfügbaren Messgrößen und übergibt sie dann an einen zentralen Prometheus Server, auf dem alle Daten zusammenlaufen.
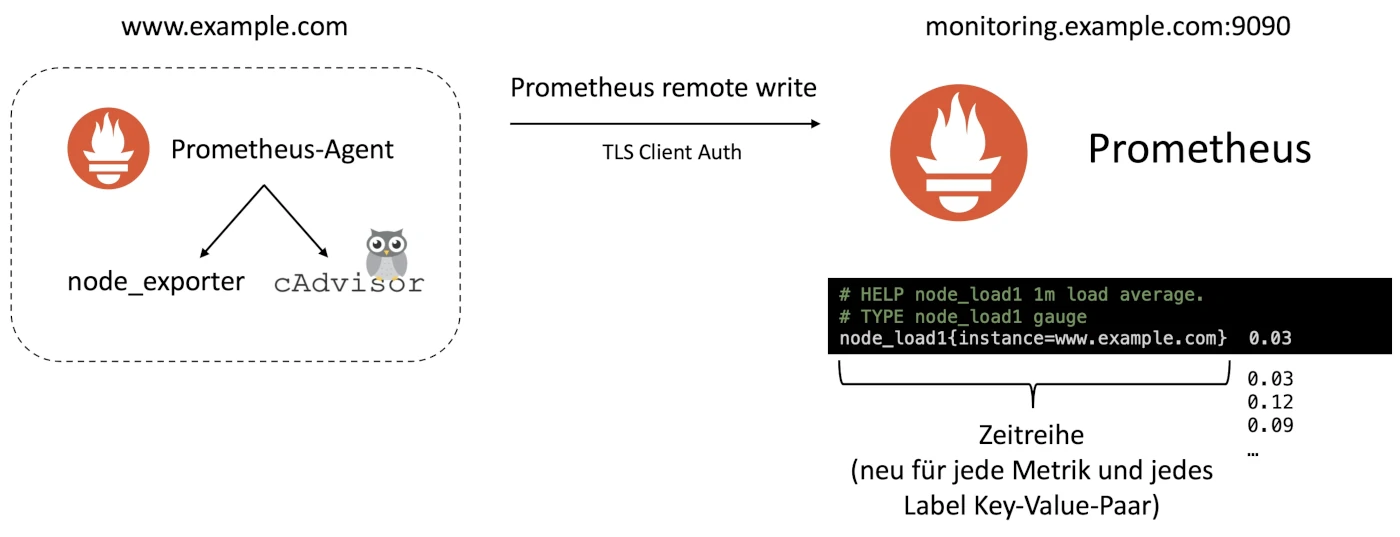
Der Vorteil an diesem Ansatz ist, dass der zentrale Server nicht über die verteilte Infrastruktur Bescheid wissen muss. Da der lokale Prometheus-Agent die gesammelten Daten für einen gewissen Zeitraum vorhält, gehen außerdem keine Daten verloren, wenn die Netzwerkverbindung kurzzeitig verloren geht. Das kann gerade dann nützlich sein, wenn unvorhergesehene Ausfälle auftreten: solche zu vermeiden ist ja gerade Sinn eines guten Monitorings, da ist es besonders ärgerlich, wenn genau dann keine Daten vorliegen, die es ermöglichen würden zu verstehen, was die Ursache eines Ausfalls war.
Den Zustand im Blick mit Dashboards und Alerts
Es ist großartig, dass wir durch den geschickten Einsatz von Open Source Software jetzt alle Messdaten unserer Kundensysteme an einem Ort haben. Noch viel wichtiger ist es aber, sie übersichtlich im Blick zu haben, um mögliche Probleme zu erkennen, bevor sie entstehen. Dabei hilft uns das Dashboarding Tool Grafana, das die wichtigsten Kenngrößen übersichtlich auf unseren großen Monitoring Bildschirm zaubert und uns erlaubt, bei Bedarf, tiefer in den Zustand einzelner Systeme zu blicken.
Damit wir nichts aus den Augen verlieren und auch nachts oder am Wochenende nichts schiefgeht, löst Prometheus für uns rechtzeitig Alarm aus, wenn sich ein Problem anbahnt. Ein diensthabender Cloud Creator wird dann automatisch übers Handy informiert und kann eingreifen, sodass der Betrieb für unsere Kunden reibungslos weiterläuft. Für weniger dringende Probleme erstellen wir Tickets in unserem Service Desk. Größere, anstehende Wartungsarbeiten stimmen wir dann mit unseren Kunden ab und führen sie so durch, dass sie den Geschäftsablauf nicht stören.
Benötigen Sie Unterstützung bei der Überwachung Ihrer Infrastruktur oder beim Betrieb Ihrer Anwendung? Dann sprechen Sie mit uns!



















